
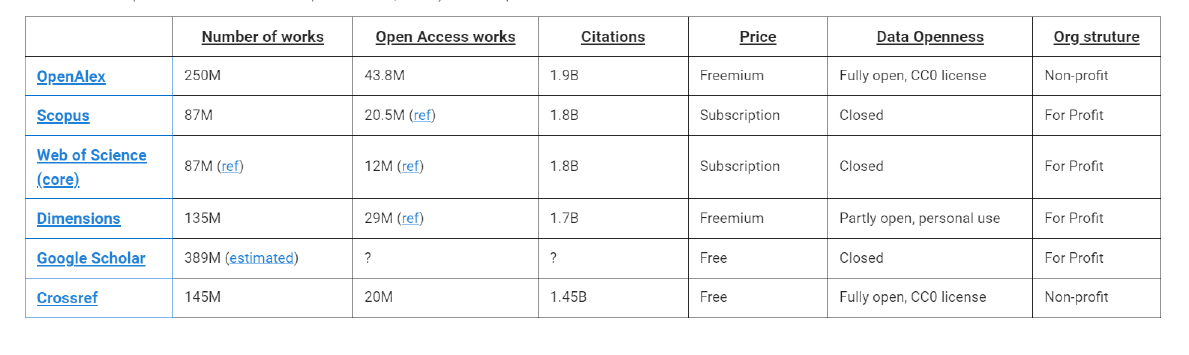
Figure 1. Tableau comparatif publié par OpenAlex.
Les contenus proviennent principalement de Microsoft Academic (qui n’est plus mis à jour) et de Crossref. D’autres sources sont également utilisées comme ORCID, ROR, DOAJ, Unpaywall, Pubmed, Pubmed Central, The ISSN International Centre et des repositories comme arXiv ou Zenodo.
En termes de corpus, OpenAlex présente donc un intérêt certain. Voyons maintenant ce qu’il en est des fonctionnalités de recherche.
Des fonctionnalités de recherche limitées
Nous avons donc testé la version Alpha du moteur qui n’en est qu’à ses débuts et n’est donc pas exempte de bugs.
Une recherche en texte libre trop limitée
Premier constat : le moteur de recherche en texte libre ne recherche que sur les titres des articles, ce qui est restrictif. De plus, il n’est pas possible d’entrer de requêtes booléennes, le moteur ne recherche que des expressions exactes.
Si on veut combiner plusieurs mots-clés dans sa recherche, il faut entrer une première requête avec un mot-clé, entrer une deuxième requête avec un deuxième mot-clé et ainsi de suite. L’ensemble des mots-clés sont ensuite automatiquement combinés par des AND.
De nombreux filtres
Là où l’outil est plus intéressant, c’est au niveau des filtres proposés qui sont nombreux.
On a donc des filtres par type de contenus, année, institution, auteurs, type d’accès, source, localisation, financement, source/corpus d’origine, nombre de citations, concepts, articles rétractés ou non, article avec un abstract ou non, etc.
Des résultats classés par date ou citations
OpenAlex permet de classer les résultats par date (du plus récent au plus ancien) ou par nombre de citations (de l’article qui a été le plus cité à celui qui l’a été le moins).
On notera également une mini fonctionnalité d’analyse qui permet de visualiser sur un graphe le nombre de documents publiés par an par rapport à nos critères de recherche.
Notre avis :
Au final, la grande force d’OpenAlex pour le moment est la taille de son corpus et la possibilité de visualiser les résultats de sa recherche par ordre antéchronologique. Sauf qu’à ce stade, le système « buggue » dès qu’on atteint la 10e page de résultats. La matière et le sourcing sont donc bien présents, mais les possibilités de recherche offertes ne permettent pas encore de l’exploiter pleinement. OpenAlex pourra être interrogé en complément aux moteurs académiques classiques à ce stade, mais on surveillera de près ses futures évolutions.
Pour aller plus loin, on signalera que les contenus d'OpenAlex peuvent aussi être récupérés, grâce au logiciel Harzing Publish or Perish, sous la forme de corpus qui pourront ensuite être analysés par des outils de text mining. Cette possibilité nous a été suggérée par un de nos lecteurs (Cc Mathieu CDOC !) en commentaire de cet article. Nous vous invitons donc à lire ce commentaire pour en savoir plus sur la méthode à suivre.