
Archives du Web : que cherche le veilleur ?
Le professionnel de l’information se retrouve confronté à la question des archives du Web quand il y a besoin de faire des recherches d’antériorité sur le Web en remontant sur plusieurs années ou dizaines d’années.
Comme nous le mentionnions au début de cet article, le problème se pose moins quand il s’agit de presse ou de réseaux sociaux (sauf quand les sites et comptes ont complètement disparu).
Mais pour le reste, il n’y a d’autre choix que de se tourner vers les archives du Web, car Google n’indexe plus ces contenus, qui ont de toute façon disparu du Web.
Le veilleur peut être confronté à différents types de besoin en lien avec les archives du Web :
- Retrouver la copie d’une page à un instant précis (le cas le plus simple) ;
- Retrouver un document (PDF, Word, etc.) publié sur une page Web à une période précise ;
- Retrouver des contenus multimédias (image, vidéo, etc.) à un moment donné ;
- Rechercher par mot-clé comme sur un moteur de recherche, mais voir apparaître des résultats anciens ;
- Rechercher un mot-clé sur une archive d’une page précise ;
Et selon les cas, les méthodologies et outils utilisés vont différer. Nous allons maintenant nous intéresser aux outils aujourd’hui à notre disposition pour répondre à ces différents besoins.
La Wayback Machine : fonctionnalités et usages
Si Internet Archive n’existait pas, le Web s’en trouverait clairement diminué et les professionnels de l’information seraient privés de nombreuses informations. Mais Internet Archive et la Wayback Machine ne répondent pas à tous les besoins de contenus anciens publiés sur le Web.
Internet Archive et ses différents services, morcelés
Le service le plus connu est la Wayback Machine.
Pour rappel, la Wayback Machine fonctionne à partir de l’url d’un site ou d’une page Web. Il faut donc déjà avoir cet élément en main quand on lance une recherche. À partir de cette url, la Wayback Machine va regarder si elle dispose d’archives de ce site/page dans sa base. L’utilisateur peut ensuite afficher les copies des pages à une date donnée.
C’est très pratique si on cherche à vérifier quand un contenu a été publié pour la première fois, si une information était publiée sur tel site à telle date, etc. Mais cela suppose de savoir :
- D'une part sur quel site on veut rechercher et il n’est pas possible de rechercher par mot-clé.
- D’autre part, la Wayback Machine ne conserve que très rarement des contenus multimédias ou des fichiers hébergés sur un site. Quand on cherche à retrouver un fichier PDF sur un site ou des images ou vidéos, le succès est rarement au rendez-vous avec la Wayback Machine. De plus, il archive mal les réseaux sociaux.
On ne le sait pas forcément, mais Internet Archive propose d’autres services et fonctionnalités liés aux archives du Web qui ne sont pas très bien mises en avant.
- Tout d’abord, il existe une fonctionnalité spéciale de la Wayback Machine pour rechercher des PDFs qui ont été à un moment donné publié sur le Web. Ces résultats n’apparaissent pas par défaut quand on recherche par mot-clé ou avec une url avec la Wayback Machine. Pour y accéder, il faudra se rendre en bas de la page d’accueil de la Wayback Machine et entrer ses mots-clés dans la zone Collection Search qui se limite aux PDFs. Le moteur recherche alors uniquement sur des PDFs (745 millions tout de même) qu’il a indexés avec les années.
C’est intéressant pour retrouver des documents anciens par mot-clé publiés sur n’importe quel site, mais la recherche est malheureusement très simpliste et il n’y a aucun filtre par date ou année par exemple.
- D’autre part, le site Internet Archive héberge également des contenus anciens qui peuvent avoir de l’intérêt. Car Internet Archive, c’est aussi une bibliothèque numérique avec des millions d’ouvrages gratuits, de films, de logiciels, de musiques et de sites Web. La recherche dans le moteur permet de rechercher des mots-clés dans les métadonnées des contenus indexés, dans le text content (ce qui permet de faire émerger des documents comme des livres blancs, plaquettes, programme de conférence, présentations, ouvrages anciens en libre accès, etc.).
- Internet Archive a aussi développé :
- Un moteur de GIFs anciens :
- Un moteur d’archive d’articles académiques avec 25 millions d’articles.
Internet Archive, ce n’est donc pas la seule Wayback Machine mais il n’en reste pas moins qu’il ne peut pas archiver l’intégralité du Web à lui tout seul et qu’il ne peut satisfaire tous les besoins informationnels des professionnels de l’information.
D’autres acteurs existent et tentent de se rendre plus visibles et de nouveaux entrants ont également émergé au cours des dernières années.
A quels besoins peuvent-ils répondre et quel peut être leur valeur ajoutée ?
Les autres acteurs des archives du Web
Les acteurs locaux et nationaux
Il y a tout d’abord les acteurs locaux, c’est-à-dire les différents services d’archives du Web développés à l’échelle d’un pays. Un grand nombre de pays disposent aujourd’hui de projets d’archivage du Web, archivage souvent mené par la bibliothèque nationale du pays.
L’intérêt de ces services, c’est qu’ils se focalisent sur l’internet du pays en question et peuvent donc offrir une meilleure couverture qu’Internet Archive au niveau local.
Mais il y a un mais… Si certains de ces services sont librement accessibles sur le Web, c’est loin d’être le cas partout. De nombreux services ne sont en effet accessibles que dans le pays en question dans les locaux de la bibliothèque nationale. L’argument avancé étant une question juridique. C’est le cas en France par exemple ou en Suède.
Ces acteurs ne sont pas nouveaux, mais on constate qu’avec les années, le nombre d’acteurs mettant à disposition leurs archives du Web librement sur le Web a augmenté.
- Parmi les archives accessibles, on pourra citer celles de l’Australie , des États-Unis avec la Library of Congress qui va bien au-delà des frontières des États-Unis et a une vraie couverture internationale ou encore celle du Royaume-Uni .
- On pourra trouver une liste des différentes archives du Web à travers le monde sur le site.
- On constatera aussi que parmi les acteurs qui ne donnent pas accès aux archives en libre accès, on pourra tout de même accéder à quelques pans d’archives du web depuis leur site. Ils proposent parfois des collections thématiques d’archives qui sont quant à elles en libre accès. La France a ainsi participé au projet d’archivage du Web international sur le Coronavirus. Et ces archives-là sont bien disponibles en libre accès.
Quand on aura besoin de retrouver des archives du Web associées à un pays particulier, on aura donc intérêt à regarder s’il existe des initiatives en la matière dans le pays. Même si les chances de succès restent minces, on n’est jamais à l’abri d’une bonne surprise.
Les initiatives internationales
On trouve de l’autre côté d’autres initiatives qui se positionnent plus comme des moteurs d’archives du Web et qui ont une couverture internationale. Certains sont nouveaux et d’autres existent depuis de nombreuses années, mais essayent de se rendre plus visibles.
Archive-it
On citera tout d’abord Archive-it qui est construit à partir des contenus d’Internet Archive. Sa principale force réside dans sa capacité à laisser l’internaute naviguer dans les contenus par collections (le tremblement de terre au Japon en 2011 par exemple) et par institutions.
Mais on oubliera ici l’idée de rechercher l’archive d’une page précise ou la recherche par mot-clé. L’outil n’est absolument pas conçu pour ça.
Archive Today
Archive Today se présente avant tout comme une machine à remonter dans le temps personnelle où l’utilisateur indique des urls qu’il souhaite sauvegarder pour un usage futur.
Mais l’outil permet également de lancer des recherches sur les pages sauvegardées dans sa base. Le moteur est construit à partir d’un Google CSE. Il a l’avantage de permettre une recherche par mot-clé ou par url.
On peut même raffiner en utilisant les syntaxes suivantes :
bases-netsources.compour une copie de l’hôte au format image*.lemonde.frpour une liste des sous-domaineshttp://twitter.com/flateampour l’url exactehttp://twitter.com/fla*pour le préfixe de l’url
Malgré ces quelques avantages, on constate que le corpus reste restreint surtout comparé à la Wayback Machine. Et quand il y a bien une archive, il n’y en a généralement qu’une seule à une date donnée.
Arquivo

Figure 1. Interface d’Arquivo
Arquivo est une archive du Web qui remonte jusqu’à 1996 et il s’agit d’une initiative portugaise (Cf. figure 1. Interface d’Arquivo). Et contrairement à d’autres initiatives locales, elle ne se focalise pas uniquement sur le Portugal même si cela représente une partie importante.
La recherche peut se faire par url ou par mot-clé.
De tous les sites liés aux archives du Web, Arquivo est le plus agréable et simple à utiliser et a l’immense avantage d’offrir une recherche par mot-clé. Mais en termes de couverture, il reste en deçà de ce que peut proposer la Wayback Machine.
Archive.eu
En 2021, le monde des archives du Web a vu l’apparition d’un nouvel acteur : European Web archive, appelé dans un premier temps European Internet Archive avant d’être rappelé à l’ordre par Internet Archive lui-même. À première vue, le site semble lié à l’Union Européenne en raison de l’utilisation du drapeau européen et d’un nom de domaine en .eu, mais il s’agit en réalité d’une initiative purement individuelle.
La recherche ne peut se faire que par url ou nom de domaine.
L’antériorité s’avère très limitée ainsi que la couverture. A ce stade, il n’y a pas de réelle valeur ajoutée à utiliser cet outil.
Time Find
Time Find est un outil développé sur Github et qui permet de rechercher par mot-clé dans l’historique d’un site Web (à partir des pages archivées par Internet Archive).
Cet outil est intéressant, car il permet de faire quelque chose qui n’est pas disponible dans la Wayback Machine : déterminer rapidement si un site a un jour cité tel ou tel mot-clé sans avoir à regarder manuellement toutes les archives disponibles pour ce site dans la Wayback Machine
L’installation est assez simple : il faut d’abord télécharger Node.js puis on entrera dans le terminal de commande de son ordinateur la requête suivante : npm install -g timefind pour installer TimeFind.
Reste ensuite à entrer sa recherche dans le terminal de la manière suivante : Timefind urldusite mot-clé
Par exemple, on entrera : Timefind www.bases-netsources.com quiz (Cf. Figure 2. Requête dans Time Find) pour savoir approximativement à quelle date les quiz ont été lancés sur le site de BASES et NETSOURCES.

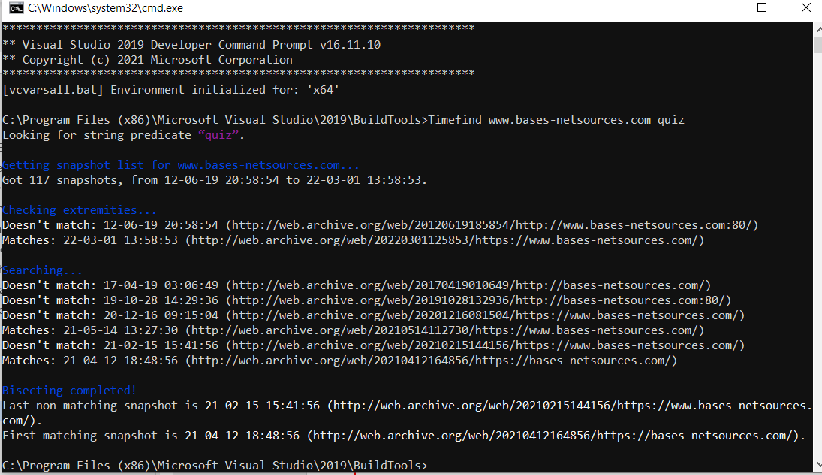
Figure 2. Requête dans Time Find
Nous l’avons testé et avons pu constater qu’en fonction des recherches, les résultats étaient plus ou moins fiables. Mais il a l’avantage de fournir une première indication qui pourra permettre de ne pas avoir à passer en revue l’intégralité des archives d’une page sauvegardées par Internet Archive.
Un outil précieux à garder sous le coude !
Finalement, on ne peut que conclure qu’Internet Archive reste le pilier et l’élément central des archives du Web. Parmi les nouveaux outils, nombreux sont ceux qui tirent parti d’une manière ou d’une autre du travail déjà réalisé par Internet Archive, mais ils offrent certaines fonctionnalités qu’Internet Archive ne propose pas. On aura donc intérêt à rester en veille pour identifier d’autres petits outils qui pourraient nous faire gagner du temps dans cette démarche.
Mais la recherche d’archives du Web reste toujours aussi compliquée et les chances de succès restent minces : retrouver les archives d’un site ou d’une page déjà identifiée reste le cas qui fonctionne le mieux. Mais la recherche d’archives multimédias ou la recherche par mot-clé sur un large corpus de pages archivées à la matière des moteurs reste peu satisfaisante et on a peu de chances d’obtenir ce que l’on cherche.