
L’enjeu de la recherche sémantique et des Knowledge Graphs pour la recherche d’information professionnelle
Derrière la question des Knowledge Graphs qui est parfois utilisée comme un argument commercial et marketing pour promouvoir une recherche d’information d’un nouveau genre, plus innovante et simplifiée, c’est plus largement la question de la place de la recherche sémantique dans la recherche d’information professionnelle qui se pose.
La recherche sémantique est en effet de plus en plus présente dans l’environnement du professionnel de l’information et, ce, quels que soient les outils de recherche et de veille qu’il utilise (grands publics comme les moteurs de recherche web ou très professionnels comme les serveurs, les agrégateurs de presse ou encore les plateformes de veille).
Quand un outil met en avant son usage des Knowledge Graphs, cela peut revêtir différentes réalités. Tous les outils ne font pas le même usage des Knowledge Graphs et tous peuvent avoir recours à des Knowledge Graphs différents. Il y a :
- les Knowledge Graph propriétaires des géants du Web qui existent depuis des années et sont sans cesse améliorés,
- des Knowledge Graphs publics qui existent depuis des années,
- des Knowledge graphs propriétaires plus récents développés par des acteurs de l’information professionnelle qui peuvent être plus spécialisés sur un type d’informations ou un secteur d’activité.
Les enjeux pour les professionnels de l’information varient donc selon le type de Knowledge Graph et surtout selon l’usage qui en est fait dans les outils.
On distinguera trois principaux enjeux pour les professionnels de l’information :
- Le premier concerne les outils de recherche grand public comme les moteurs de recherche généralistes qui ont basculé sur un modèle de recherche sémantique à base de Knowledge Graphs depuis déjà de nombreuses années. Et la conséquence directe, c’est que l’internaute a de plus en plus de mal à rechercher traditionnellement par correspondance de mots-clés. La recherche sémantique, qui n’est pourtant pas exempte d’erreurs et de problèmes d’interprétation, a supplanté la recherche par correspondance de mots-clés classique. Et de ce point de vue-là, cela peut être préjudiciable pour la recherche d’information professionnelle. Comment continuer à bien rechercher dans des outils qui ont fait ce choix ?
- Le second concerne les Knowledge Graphs publics comme Wikidata ou DBpedia. Wikipédia est une source d’information précieuse pour la recherche et la veille et les Knowledge Graph Wikidata et DBpedia ont cette capacité à pouvoir faire émerger des liens entre les données et informations présentes dans Wikipédia. Comment peut-on tirer parti de cette richesse pour rechercher de l’information alors même que ces Knowledge Graphs sont difficiles d’accès pour des non-initiés ?
- Enfin, le troisième concerne les outils de recherche et de veille professionnels qui intègrent de plus en plus de Knowledge Graphs et plus largement de recherche sémantique dans leurs produits. Ces acteurs ont privilégié une approche différente : ne pas faire table rase du passé. La recherche sémantique coexiste avec la recherche traditionnelle par mot-clé, la machine et l’humain sont complémentaires et c’est cela qui peut être très puissant pour la recherche d’information professionnelle. Comment tirer parti du meilleur des deux mondes en continuant à pratiquer des recherches expertes doublées d’une recherche sémantique ?
Maintenant que nous avons mis en évidence les différents enjeux des Knowledge Graphs pour la veille et la recherche d’information professionnelle, nous allons désormais explorer en détails ce que sont les Knowledge Graphs et leur positionnement dans le paysage de la recherche sémantique.
Comprendre les Knowledge Graphs et leurs usages
Qu’est ce qu’un Knowledge Graph ?
Si le terme Knowledge Graph apparaît souvent, on ne sait pas pour autant ce qui se cache précisément derrière ce terme.
Les Knowledge Graphs sont des gigantesques bases de données qui permettent une représentation de la connaissance dans un format graphique. Les entités du monde réel ou d'un domaine d'activité (personnes, lieux, événements) sont représentés par des nœuds (nodes), qui sont reliés entre eux pour représenter les relations entre ces différentes entités.
On trouve sur le Web de nombreuses infographies et schémas qui tentent de représenter visuellement le fonctionnement d’un Knowledge Graph. Nous en reproduisons une ici que nous trouvons parlante, proposée par Amazon Web Services (cf. Figure 1. Fonctionnement d’un Knowledge Graph).
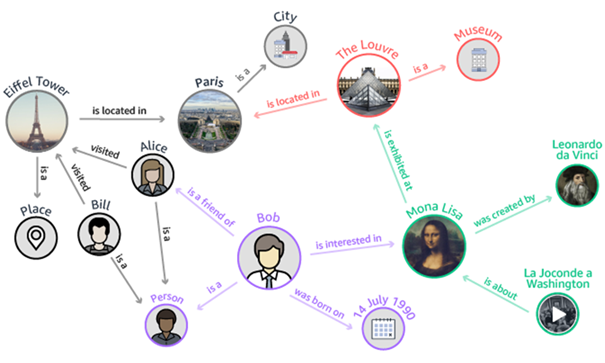
Figure 1. Fonctionnement d’un Knowledge Graph (source : https://aws.amazon.com/fr/neptune/knowledge-graphs-on-aws/ )
Il n’existe pas UN mais DES Knowledge Graphs
Il existe de nombreux Knowledge Graphs très différents les uns des autres.
Certains sont publics et librement réutilisables comme Wikidata ou DBpedia qui se fondent sur les informations présentes dans Wikipédia, d’autres sont propriétaires comme ceux utilisés par les géants du Web (Google Facebook, Microsoft, Ebay ou encore Netflix).
Certains sont généralistes, d’autres spécialisés sur un secteur ou un domaine ou sur un type d’entités (les personnes, les lieux comme Geonames par exemple).
Leur taille et le nombre d’entités et de liens est également très variable.
Les Knowledge Graphs ont vocation première à être utilisés en arrière-plan d’un outil ou d’une application, au même titre que d’autres technologies, pour venir en enrichir les informations et faire émerger des connexions entre les données et en extraire de la valeur.
Une rapide histoire des Knowledge Graphs
La technologie des Knowledge Graphs n’est pas nouvelle et l’un des plus ancien, appelé Cyc, date des années 90. Le terme est devenu populaire quand Google a annoncé introduire un Knowledge Graph dans son moteur en 2012. Google n’est d’ailleurs pas parti de zéro et avait racheté en 2010 Metaweb et son Knowledge Graph appelé Freebase.
Amazon avait fait de même en rachetant en 2012 True Knowledge et son Knowledge Graph Evi qui est aujourd’hui utilisé par Alexa, l’assistant vocal d’Amazon.
De son côté, Microsoft avait développé son propre Knowledge Graph appelé Satori qui est aujourd’hui utilisé dans Bing et Cortana.
La place des Knowledge Graphs par rapport à l’IA, la taxonomie, les ontologies
Il n’est pas simple de positionner les Knowledge Graphs par rapport aux autres concepts gravitant autour de la recherche sémantique. C’est pour cela que nous avons choisi ici de proposer un petit lexique pour bien distinguer le concept par rapport aux autres éléments qui l’entourent.
Nous nous sommes fondés sur les définitions proposées par le site Innodata qui nous paraissaient les plus accessibles et compréhensibles pour des non-initiés.
Taxonomie : Une taxonomie est la classification des données en catégories et sous-catégories. Elle fournit une vue unifiée des données d'un système et introduit des terminologies et une sémantique communes à plusieurs systèmes. Les taxonomies représentent la structure formelle des classes ou des types d'objets dans un domaine. Une taxonomie est statique.
Ontologie : Une ontologie est une convention de dénomination formelle et la définition des types, propriétés et interrelations des entités qui existent réellement ou fondamentalement dans un domaine en particulier. Une ontologie est dynamique et centrée sur un domaine en particulier.
Knowledge Graph : Un Knowledge Graph est un modèle d'un domaine de connaissances créé par des experts en la matière à l'aide d'algorithmes de machine learning. Il fournit une structure et une interface commune pour toutes les données et permet la création de relations multilatérales dans les bases de données. Structuré comme une couche de données virtuelle supplémentaire, le Knowledge Graph se superpose aux bases de données existantes - ou aux datasets - pour relier toutes les données entre elles, qu'elles soient structurées ou non.
Knowledge Graph et IA sont liés dans le sens où le machine learning est utilisé pour construire et structurer les Knowledge Graphs mais aussi pour déduire des liens entre des nœuds qui ne seraient pas remarqués autrement. Et inversement, le machine learning tire aussi bénéfice des Knowledge Graphs notamment pour mieux comprendre en profondeur certaines données comme le texte, le format vidéo ou audio.
Les Knowledge Graphs ont donc une place importante pour tout ce qui a trait à la recherche sémantique même s’ils ne sont pas systématiquement utilisés par les outils et applications proposant de la recherche sémantique.
Quel usage pour la recherche d’information ?
Dans un monde où l’information non structurée reste majoritaire (on voit souvent le chiffre de 80% d’informations non structurées mais cette donnée est difficilement vérifiable), les Knowledge Graphs font donc partie de la solution pour transformer des données non structurées en données structurées et ainsi simplifier la recherche et l’identification de ces contenus.
Un récent article scientifique de 2020 intitulé « Knowledge Graphs: An Information Retrieval Perspective » s’est justement intéressé à l’apport des Knowledge Graphs dans un contexte de recherche d’information.
On précisera tout de même que les auteurs s’intéressent ici à la recherche d’information au sens de la discipline informatique et non à la recherche d’information pratiquée par des professionnels de l’information. Mais bon nombre des usages cités restent valable et pertinents pour la recherche d’information professionnelle.
Les auteurs y expliquent que les Knowledge Graphs sont essentiels pour permettre la recherche sémantique.
L’utilisation de Knowledge Graph dans un outil de recherche va permettre :
- D'améliorer la compréhension des documents ;
- D’améliorer la compréhension de l'intention et des requêtes d'un utilisateur, au-delà de ce qui peut être réalisé avec une requête par mot-clé classique ;
- De répondre à des besoins d’informations qui nécessitent une réponde directe et non une liste de liens (date de naissance d’une personne, le nombre de villes de plus de 5000 habitants, etc.) ;
- D’explorer des entités connexes mentionnées dans une collection de documents ou une page de résultats ;
- D’aider à fournir des explications sur les entités et les relations dans leur contexte afin d'aider davantage l'utilisateur.
En résumé, cela permet de proposer des résultats qu’il aurait été plus difficile de repérer avec une recherche classique par correspondance de mots-clés.
Exemple :
Quand on entre la requête London Weather, le moteur va alors être capable d’identifier les entités de la requête puis les rechercher dans le Knowledge Graph et de choisir l’entité la plus populaire, c’est-à-dire ici la capitale du Royaume-Uni.
Comment les Knowledge Graphs ont changé la façon de rechercher l’information chez les géants du Web
Comme nous l’avions mentionné en début d’article, certains Knowledge Graphs existent depuis déjà une dizaine d’années. C’est le cas des Knowledge Graphs publics mais aussi des outils de recherche proposés par les géants du Web comme Google, Bing, Amazon, eBay, etc.
Google et son Knowledge Graph : le moment où Google est devenu un moteur de réponses
Comment se matérialise-t-il ?
Google a abondamment communiqué sur l’usage de son Knowledge Graph dans son moteur lorsqu’il l’a introduit en 2012. C’est d’ailleurs à ce moment-là que le moteur a pris un virage vers la recherche sémantique et que la façon de rechercher sur Google a drastiquement changé.
Le slogan utilisé par Google à l’époque était « Things not strings », l’idée étant que les chaînes de caractères sont par nature ambiguës (Orange fait par exemple référence à plusieurs entités) alors que le Knowledge Graph est constitué d’entités désambiguïsées.
C’est à ce moment-là que Google est passé d’un moteur de recherche à un moteur de réponses.
En 2020, Google indiquait que son Knowledge Graph contenait 5 milliards d'entités et 500 milliards de faits. Parmi ses sources, il y a évidemment Wikipédia, CIA Factbook mais Google indique également utiliser des centaines d’autres sources (et même des sources sous licence) notamment spécialisée (comme pour le médical par exemple).
Le Knowledge Graph de Google se matérialise aujourd’hui sous la forme du Knowledge Panel (l’encadré sur la droite des résultats de recherche), qui s’affiche quand on recherche une personne, une entreprise, marque, lieu ou encore un objet. Il est aussi utilisé dans Discover sur l’app Google sur mobile pour déterminer les sujets (Topics) plébiscités par l’internaute et afficher des contenus en lien avec ces sujets.
Quel impact pour la recherche d’info professionnelle ?
Dans un contexte de recherche d’information professionnelle, le Knowledge Panel tout comme la page d’accueil Discover sur mobile sont d’une utilité toute relative. On glanera au mieux quelques informations élémentaires quand on débute sur un sujet.
L’autre intérêt quand on lance une recherche, c’est de vérifier que Google a bien compris à quelle entité on faisait référence. Ainsi, si on effectue une recherche sur le terme Orange en voulant faire une recherche sur les fruits et que Google affiche dans le Knowledge Panel des informations sur la société, cela montre que Google n’a pas compris et qu’il faut impérativement reformuler sa requête.
Pour information, ce qui est affiché dans le Knowledge Panel ne dépend pas de l’historique de l’internaute. Toute personne entrant la requête Orange aura par défaut des informations sur la société et non sur la couleur ou le fruit. Google attribue un score aux entités portant le même nom et fait ressortir en premier celle qui a le plus de chances d’être recherchée par l’internaute.
Et dans ce cas, pour rechercher sur la bonne entité, on peut reformuler sa requête en mettant Orange fruit.
On peut aussi forcer Google à afficher la bonne entité de son Knowledge Graph en tirant parti d’outils externes.
Utiliser Kalicube pour influencer la recherche d’entités sur Google
Kalicube propose un outil gratuit appelé Knowledge Graph Explorer et qui permet de rechercher sur les marques et personnes présentes dans le Knowledge Graph de Google.
Ainsi, si l’on entre le terme Orange dans Kalicube, le moteur nous propose plusieurs entités classées par popularité :
- L’entreprise Télécom Orange ;
- EE, un autre opérateur téléphonique qui a un temps appartenu à Orange ;
- Orange le fruit ;
- Une équipe de basket, la « Syracuse Orange men's basketball » ;
- Orange County, un comté aux Etats-Unis ;
- Orange, la couleur.
Pour chaque entité, on dispose alors d’un ID et de la possibilité de visualiser les résultats associés à cette entité sur Google.
Exemple :
On peut aussi entrer l’ID directement dans l’url de Google sous le format suivant :
https://www.google.de/search?kgmid=Kalicube nous indique que l’ID pour la société Orange est
/m/0jd05Il suffira donc d’écrire
https://www.google.de/search?kgmid=/m/0jd05pour accéder aux résultats Google associés à cette entité.Pour cet exemple, on constate que lancer une simple requête Orange dans Google ou utiliser spécifiquement l’url
https://www.google.de/search?kgmid=/m/0jd05fournit des résultats très similaires. Cela s’explique sûrement pas le fait que, par défaut dans Google, c’est l’entité Orange (entreprise) qui est privilégiée par le moteur.
A l’inverse, si on recherche sur l’entité EE et si on fait une autre recherche en texte libre sur EE dans Google, les résultats sont ici complètement différents.
Nous avons fait un autre test sur Stéphane Richard, le PDG actuel d’Orange. Kalicube, nous permet de voir qu’il existe plusieurs entités associées à ce nom et prénom. Le PDG d’Orange bien sûr mais également d’autres personnalités ayant une visibilité bien moins importante et notamment un chercheur.
Une recherche sur Stéphane Richard dans Google fournira une très grande majorité de résultats sur le PDG d’Orange.
En forçant Google à rechercher sur l’entité Stéphane Richard (chercheur) avec l’url suivante
https://www.google.com/search?kgmid=/g/11h99mjzsg, on visualisera alors des résultats sur cette personne et non le PDG d’Orange, résultats qui n’avaient pratiquement aucune chance d’apparaître avec une recherche standard sur Google.Ainsi quand on recherche des informations sur une personne, entreprise, un lieu ou encore un objet, on a tout intérêt à tester des requêtes sur les entités en tirant parti d’outils comme Kalicube afin d’avoir des résultats différents mais aussi désambiguïser les résultats dans certains cas.
Utiliser Google CSE pour tirer parti du Knowledge Graph
Il existe un autre moyen de tirer parti du Knowledge Graph, c’est en utilisant le moteur personnalisé de Google, Google CSE. Nous en avions déjà parlé dans l’article « Comment construire ses propres outils de recherche d’information thématiques ? » (NETSOURCES n°144 – janvier-février 2020). Cette fonctionnalité existe depuis 2019.
Lors de la construction du moteur CSE, Google offre la fonctionnalité suivante : « Limiter les pages à l'aide d'entités Knowledge Graph ».
Il est possible d’ajouter 5 entités maximum (par exemple Orange (entreprise), Stéphane Richard (PDG), etc.). Les 5 entités sont séparées par un OR par défaut.
La recherche ne portera alors que sur les pages web auxquelles sont associées au moins une de ces entités (ce qui est déterminé automatiquement par Google).
Encore une fois, cela pourra permettre de faire ressortir des résultats qui ne seraient pas apparus avec une recherche classique dans le moteur de Google.
Le Knowledge Graph prochainement utilisé dans Google Images
A l’été 2020, Google a communiqué sur l’intégration du Knowledge Graph dans Google Images. Mais cela n’était disponible que sur mobile aux Etats-Unis. Un an après, cela ne semble toujours pas disponible en Europe.
Lorsqu’un internaute recherche une image, il peut obtenir des informations complémentaires liées à l’image (personnes, lieux ou objets) issues du Knowledge Graph.
Google propose l’exemple suivant : si on recherche des parcs nationaux à visiter aux Etats-Unis, l’internaute peut cliquer sur une image montrant un parc avec une rivière. Grâce au Knowledge Graph, on pourra voir des éléments, comme le nom de la rivière ou la ville dans laquelle se trouve le parc. Ces éléments permettront ensuite d’obtenir directement une brève description de la personne, du lieu ou de la chose à laquelle il fait référence, un lien pour en savoir plus, ainsi que d'autres sujets connexes que l’internaute pourra explorer.
Les autres géants du Web et leurs Knowledge Graphs
Les autres géants du Web utilisent des Knowledge Graphs mais l’internaute n’y a pas directement accès, ils sont complètement intégrés aux outils. Il est cependant intéressant de comprendre l’utilisation qui en est faite chez ses outils.
Facebook utilise un Knowledge Graph pour mettre en évidence les réseaux de personnes et les liens entre les entités (sujets les plus discutés par ses utilisateurs par exemple). En plus d'utiliser un Knowledge Graph pour découvrir les connexions sociales entre les utilisateurs et leur donner des recommandations sur leurs intérêts sociaux, Facebook utilise un Knowledge Graph pour répondre aux requêtes en langage naturel des utilisateurs.
Netflix utilise un Knowledge Graph pour organiser les informations dans son catalogue de contenu, en déduisant les liens entre les émissions de télévision, les films et les réalisateurs, producteurs et acteurs. Cela permet ensuite de déduire ce que les utilisateurs pourraient aimer regarder ensuite et ainsi leur proposer des recommandations.
Le Knowledge Graph de LinkedIn est une grande base de connaissances construite à partir des entités de LinkedIn, telles que les membres, les emplois, les titres, les compétences, les entreprises, les lieux géographiques, les écoles, etc. Ces entités et les relations qu'elles entretiennent entre elles forment l'ontologie du monde professionnel et sont utilisées par LinkedIn pour améliorer ses systèmes de recommandation, ses recherches, etc. (LinkedIn avait communiqué sur son Knowledge Graph en 2016).
Les Knowledge Graphs ne sont pas sans faille
Les Knowledge Graphs ne sont pas sans faille et les informations qui en sont issues peuvent contenir des erreurs.
Une récente étude datant de 2021 appelée « An Investigation of the Accuracy of Knowledge Graph-base Search Engines: Google knowledge Graph, Bing Satori and Wolfram Alpha » s’est justement intéressée à la véracité des informations issues des Knowledge Graphs.
Google, Bing et Wolfram Alpha (qui ne fonctionne pas sur un modèle de Knowledge Graph mais de Computational Knowledge System) ont ainsi été comparés à partir d’un certain nombre de requêtes répliquées dans les trois moteurs.
D'après les résultats :
- Google produit un total de 124 résultats pertinents, 13 résultats non pertinents ou incorrects et 12 des 149 requêtes n'ont produit aucun résultat.
- Satori produit un total de 97 résultats pertinents, 29 non pertinents et 23 requêtes n'a aucun résultat.
- Enfin, Wolfram Alpha produit un total de 74 résultats pertinents, 45 non pertinents et 30 requêtes sans résultat.
Exemple :
Pour une recherche pour identifier l’auteur du livre « L’âge de Raison » (la recherche a été effectuée en anglais sur le titre « The Age of Reason ») ne fait pas émerger le bon nom d’auteur. L’auteur de l’Âge de raison est Jean-Paul Sartre mais Google et Bing indique qu’il s’agit de Thomas Paine qui a en réalité écrit un ouvrage intitulé « The Age of Reason: Being an Investigation of True and Fabulous Theology ».
Au final, c’est Google qui fournit le plus de résultats justes, suivi de Bing puis Wolfram Alpha assez loin derrière. Mais il y a tout de même des erreurs dans chacun des systèmes, ce qui rappelle qu’il faut toujours croiser ces informations même quand elles proviennent d’un Knowledge Graph.
Knowledge Graphs publics : peut-on en tirer parti pour la recherche d’information et la veille ?
Parallèlement aux Knowledge Graphs propriétaires des GAFAMs, il existe des Knowledges Graphs publics et librement réutilisables comme DBPedia, Wikidata, Yago, Nell, Caligraph et même Voldemort qui existent depuis de nombreuses années.
Pour en savoir plus sur ces Knowledge Graphs publics et leurs différents positionnements, nous conseillerons la lecture d’un article scientifique datant de 2020 intitulé « Knowledge Graphs on the Web - an Overview ».
Ces Knowledge Graphs publics n’ont pas vocation première à être utilisés par les internautes comme des outils de recherche mais à être utilisés dans des outils de recherche, des applications ou plateformes pour en améliorer la recherche.
Pourtant, la quantité d’informations et les liens qui sont fait entre les différents éléments dans ces Knowledge Graphs (notamment ceux qui se fondent sur Wikipédia) pourraient avoir un intérêt dans le cadre d’une recherche d’information, en faisant émerger des liens entre des données ou en agrégeant des données qui existent de manière séparée.
Il existe ainsi quelques outils permettant d’explorer Wikidata et DBPedia, qui rappelons-le se fondent sur les contenus de Wikipédia.
Wikidata Query Service proposé par Wikidata lui-même.
Seul problème, l’interrogation suppose de connaître le langage de requête SPARQL qui permet de rechercher des données RDF (classiquement utilisées par les Knowledge Graphs) disponibles sur Internet. Heureusement, l’outil propose une rubrique « exemples » permettant d’utiliser des requêtes déjà préconstruites que l’on pourra légèrement modifier en fonction de ses besoins.
Exemple :
Il n’existe pas de moyen simple et direct pour repérer toutes les personnalités qui ont eu à la fois un Oscar et un prix Nobel sur Wikipédia. Mais un Knowledge Graph peut répondre à ce type de questions en faisant le lien entre les différentes entités (les personnalités et les distinctions).
Pour rechercher les personnes qui ont à la fois reçu un Oscar et un prix Nobel, la requête s’écrira de la manière suivante (cf Figure 2. Requête SPARQL pour rechercher les personnes ayant reçu un Oscar et un prix Nobel)
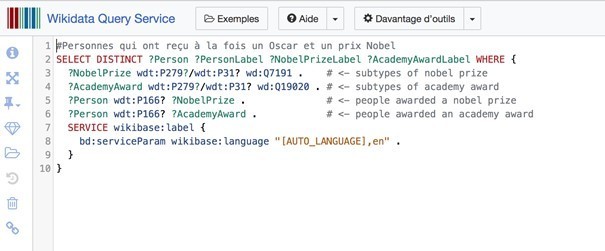
Figure 2. Requête SPARQL pour rechercher les personnes ayant reçu un Oscar et un prix Nobel
Pour aller plus loin, Wikidata propose un tutoriel pour savoir rechercher en SPARQL : https://www.wikidata.org/wiki/Wikidata:SPARQL_tutorial
Au moment où nous bouclions cet article, Wikidata a annoncé le lancement d’une nouvelle interface qui a vocation à coexister avec la première pour les personnes ne maîtrisant pas SPARQL :https://query.wikidata.org/querybuilder/.
Elle ne permet pas de faire des recherches aussi poussées mais c’est un bon moyen de débuter (cf Figure 3. Nouvelle interface de recherche pour Wikidata).
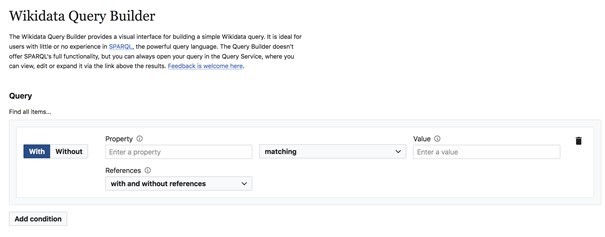
Figure 3. Nouvelle interface de recherche pour Wikidata
FactForge proposé par DBPedia
Dans la même veine, on citera également FactForge qui se fonde sur DBPedia, Geonames, WorldFacts et Wordnet mais aussi sur les données issues des Panama Papers. Il est spécialisé sur la recherche de personnes, organisations et lieux.
Mais là encore, il faut savoir faire des requêtes SPARQL même si l’outil propose également quelques exemples (cf. Figure 4. Requête sur Factforge pour repérer les personnes et organisations liées à Google).
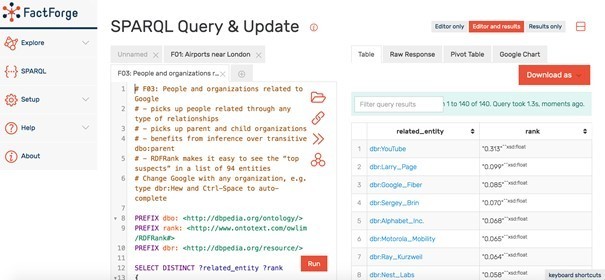
Figure 4. Requête sur Factforge pour repérer les personnes et organisations liées à Google
La place et l’utilité des Knowledge Graphs dans les outils professionnels
On trouve de plus en plus d’acteurs du monde de l’information professionnelle qui indiquent avoir recours à des Knowledge Graphs dans leurs outils de recherche. Certains sont de nouveaux acteurs qui lancent un nouveau produit fondé sur cette technologie (comme IP Rally pour la recherche brevet – il fera l’objet d’un article à part dans un prochain numéro de BASES) ; d’autres acteurs en place choisissent de l’intégrer à des produits déjà existant à l’occasion de la refonte du système (comme chez EBSCO par exemple) ou développent un produit à part, comme Dow Jones DNA, qui est distinct de Factiva.
Certains acteurs indiquent avoir recours à la recherche sémantique depuis longtemps mais le terme de Knowledge Graph n’apparaît dans leur communication que depuis un ou deux ans. Il est difficile de déterminer à quel moment ils se sont réellement mis à l’intégrer et si le terme n’a pas commencé à être utilisé au moment où cette technologie est devenu plus « vendeuse ». Le célèbre cabinet Gartner qui publie chaque année une étude sur les technologies émergentes a commencé à intégrer les Knowledge Graphs à partir de 2018.
Les outils de recherche et de veille professionnels semblent pour la plupart faire appel à des entreprises qui proposent des « Graph as a service » pour créer et implémenter leurs Knowledge Graphs. Parmi les noms que l’on retrouve régulièrement, on citera : Neo4j, TigerGraph, Datastax Enterprise Graph, JanusGraph, Stardog. Microsoft, IBM ou encore Amazon Web Services commercialisent également ce type de solution.
Quand les serveurs introduisent des Knowledge Graphs : le cas d’EBSCO
Chez EBSCO, la notion de Knowledge Graph est apparue lors du lancement de la nouvelle interface d’EDS (EBSCO Discovery Services).
Même si cela semble s’adresser plus au chercheur d’information novice plutôt qu’aux experts, il n’en reste pas moins que cette recherche sémantique peut être complémentaire aux recherches classiques par mots-clés.
Grâce à son Knowledge Graph, EBSCO propose également depuis peu une fonctionnalité « Concept Map » (cf Figure 5. Concept Map d’EBSCO), une fonctionnalité de dataviz qui permet de naviguer dans les concepts et sujets similaires et permet ensuite d’aller enrichir sa requête.
On trouvera une vidéo de présentation de la « Concept Map ».
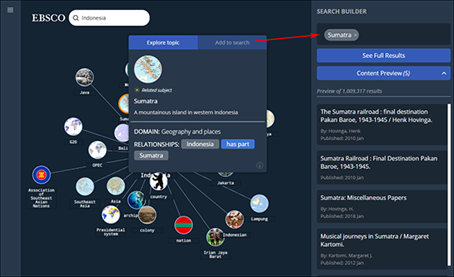
Figure 5. Concept Map d’EBSCO
Les Knowledge Graphs au service de l’actualité
Dow Jones DNA : le knowledge graph de l’information business
De son côté, Dow Jones a fait le choix de proposer un service distinct de Factiva appelé DNA (Data, News and Analytics). Le service a été lancé en 2017 mais ce n’est qu’à partir de 2019 que Dow Jones utilise le terme Knowledge Graph dans sa communication en parlant de DNA comme d’un « Knowledge Graph de l’information business ».
« Il permet aux clients de Dow Jones de réaliser des extractions de jeux de données volumineux provenant de plus de 30 000 sources. La plateforme DNA agrège les contenus des publications de Dow Jones avec les contenus de sources tierces. Les extractions de données peuvent porter sur des données préexistantes ou être remises en temps réel. L’analyse des big data ainsi récupérées permet d’identifier des tendances marchés, d’accroître des modèles de trading dans l’investissement boursier, de faire de la veille concurrentielle, de détecter des opportunités d’investissement ou d’évaluer des risques en temps réel. » (Source).
IBM Watson News Explorer
Lancé en 2015, IBM Watson News Explorer est un outil de recherche sur l’actualité fondé sur un Knowledge Graph (cf Figure 6. IBM Watson News Explorer). Il permet de rechercher puis de naviguer dans l’actualité à partir des entités repérées dans les articles de presse.
Seul bémol : l’outil n’a qu’une antériorité de 28 jours et se limite aux contenus en anglais.
Mais c’est un excellent outil pour débuter une recherche sur l’actualité en anglais et repérer les concepts importants et quelques articles pertinents.
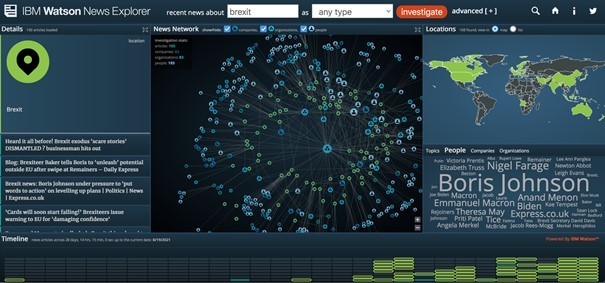
Figure 6. IBM Watson News Explorer
Il n’est pas sans rappeler un autre outil qui s’appelle Silobreaker que nous avions présenté il y a quelques années. L’outil existe toujours mais est aujourd’hui complètement passé sur un modèle payant et s’est considérablement professionnalisé.
Les Knowledge Graphs du côté des outils de veille
Le lecteur RSS Feedly a récemment communiqué (en juin 2021) sur l’usage d’un Knowledge Graph dans son assistant intelligent appelée Leo et notamment pour la fonctionnalité « Leo Web Alert ».
Feedly le présente de la manière suivante : « Au lieu de vous fier aux mots-clés, vous pouvez exploiter le Knowledge Graph de Leo, qui est la somme de tous les concepts et sujets que Leo a été formé à comprendre. »
Lorsque l’on créé une alerte web, Leo analyse en permanence des millions d'articles et ceux qui répondent aux sujets et concepts choisis par l’internaute (et pas seulement des mots clés).
Exemple :
Si on crée une alerte sur Amazon (l'entreprise) et l'intelligence artificielle (le sujet), Leo reconnaît Amazon comme une entreprise et ne signalera donc que les articles concernant Amazon l'entreprise, et non la rivière Amazon (en anglais). En ce qui concerne l'intelligence artificielle, Leo a été formé pour comprendre ce concept plus large et recherchera des centaines de termes différents liés à ce sujet.
L’internaute a la possibilité de continuer à rechercher par mot-clé de manière traditionnelle mais aussi d’inclure des entités issues du Knowledge Graph.
D’autres acteurs de la veille mentionnent également les Knowledge Graphs dans leur communication comme Market Logic, une plateforme de Competitive Intelligence (voir notre article « Les plateformes de veille internationales peuvent-elles intéresser les veilleurs francophones ? – NETSOURCES n°147 – juillet/août 2020). On en retrouve également une trace chez Meltwater, par exemple dans leurs offres d’emplois à destination d’ingénieurs informatiques.
Les Knowledge Graphs au service de l’IST et des brevets
L’IST n’est pas non plus en reste et on voit régulièrement des outils mettre en avant leur usage de Knowledge Graph.
On pourra citer notamment :
- IP Rally, un nouvel outil de recherche brevet qui nous détaillerons dans un prochain numéro.
- Yewno (https://www.yewno.com/education) propose une plateforme multidisciplinaire fondée sur un Knowledge Graph. La plateforme Discover de Yewno exploite des centaines de millions de connexions sémantiques et de liens conceptuels provenant de millions d'articles académiques, de livres et de bases de données dans tous les domaines universitaires. Cela permet aux étudiants et aux chercheurs de naviguer entre les concepts, les relations et les disciplines.
- Inspec utilise également un Knowledge Graph depuis 2019 dans son produit Inspec Analytics. Inspec Analytics utilise les technologies sémantiques pour connecter les éléments issus de la littérature scientifique et créer un Knowledge Graph afin d'identifier et de comparer les tendances de la recherche parmi des milliers d'organisations et de concepts scientifiques.
Conclusion
Les professionnels de l’information vont être de plus en plus confrontés à la question de la recherche sémantique et des Knowledge Graphs et ce, quels que soient les outils de recherche et de veille qu’ils utilisent. Et c’est pour cette raison qu’il est important de comprendre cet univers qui peut vite s’avérer très technique et quelque peu indigeste.
Il faut de plus en plus comprendre ce qui se cache sous le « capot » d’un outil car il y a finalement du bon comme du moins bon. Derrière un même concept, on trouve des solutions très avancées et réfléchies qui répondent véritablement aux problématiques des professionnels de l’information, d’autres qui sont plutôt conçues pour le grand public mais qui peuvent avoir un usage pour les professionnels et enfin des acteurs qui incluent tous les termes à la mode dans leur communication mais dont l’outil s’avère finalement très décevant au niveau technique.
Et cela s’applique également aux Knowledge Graph. Le concept est tendance et vendeur, cela rassure dans le sens où l’on a le sentiment que la technologie utilisée est structurée et transparente en opposition avec les outils à base d’IA qui s’apparentent à de véritables boîtes noires. Mais il ne faut pas hésiter à poser des questions aux outils qui mettent en avant l’usage d’un Knowledge Graph pour comprendre ce qui se cache derrière et si cela peut avoir une valeur ajoutée par rapport à ses propres besoins et usages.
Dans certains cas, l’usage d’un Knowledge Graph apporte une réelle plus-value à l’outil et c’est globalement ce que l’on peut voir dans les outils de recherche et de veille professionnels qui ont su trouver une complémentarité entre recherche par correspondance de mots-clés classique et recherche sémantique.
Dans d’autres cas comme pour les moteurs de recherche Web, on est obligé de faire avec mais c’est parfois plus un mal qu’un bien. Le passage à la recherche sémantique permet indéniablement de repérer des informations que l’on aurait manqué par une recherche par correspondance de mots-clés classiques. Mais on passe aussi à côté d’informations et résultats pertinents que la recherche sémantique n’aura pas permis d’identifier.